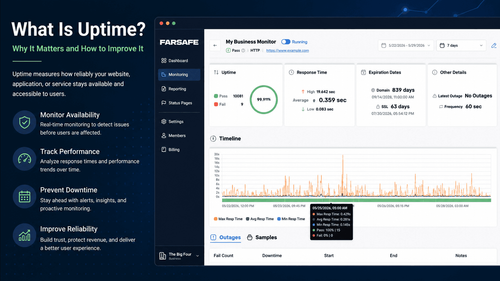
Whether you run a business website, an online store, a SaaS platform, or a critical internal application, reliability matters. Customers expect services to be available whenever they need them, and even a brief outage can lead to lost revenue, frustrated users, and damage to your brand's reputation.
This is where uptime becomes important. Uptime is one of the most widely used metrics for measuring the reliability and availability of digital services. Organizations use it to evaluate how consistently their websites, applications, servers, and networks remain operational over time.
While many businesses focus on performance, security, and growth, maintaining high uptime is equally important. A reliable service not only improves customer satisfaction but also supports business continuity and operational resilience.
In this guide, you'll learn what uptime is, how it is calculated, why it matters, what causes downtime, and proven strategies organizations can use to improve uptime and reduce disruptions.
What Is Uptime?
Uptime refers to the amount of time a system, service, website, application, or network remains operational and accessible to users. It is typically expressed as a percentage that represents how often a service is available during a specific period.
For example, if a website remains available for nearly an entire year with only a few minutes of interruption, it may achieve an uptime rate of 99.99%. The higher the percentage, the more reliable the service is considered to be.
Organizations use uptime as a key performance indicator because it provides a clear way to measure service reliability. It helps businesses understand whether their technology infrastructure is meeting user expectations and supporting daily operations without interruptions.
Understanding the Definition of Uptime
Although uptime is often associated with websites, it applies to many different types of systems and services, including:
- Websites
- Web applications
- Cloud services
- Servers
- Computer networks
- Databases
- Communication platforms
In each case, uptime measures whether the service is functioning as intended and available when users need it.
For example, an e-commerce website with high uptime allows customers to browse products and complete purchases without interruption. Similarly, a cloud-based business application with strong uptime enables employees to access critical tools throughout the workday.
Businesses that want to improve reliability often monitor their website uptime regularly to identify issues before they impact users. If you're looking for practical ways to track availability, check out our guide on how to check website uptime for free.
Uptime vs. Downtime
Uptime and downtime are closely related but represent opposite conditions.
Uptime refers to periods when a service is functioning normally and remains available to users.
Downtime refers to periods when a service becomes unavailable, inaccessible, or unable to perform its intended function.
Downtime can be planned or unplanned.
Planned downtime typically occurs during scheduled maintenance, software upgrades, or infrastructure improvements.
Unplanned downtime is usually caused by unexpected issues such as hardware failures, software bugs, cyberattacks, network outages, or human error.
Both metrics are important because they help organizations evaluate overall service reliability and identify areas for improvement.
How Is Uptime Calculated?
Organizations typically calculate uptime as a percentage of total operating time. The calculation compares the amount of time a service remains available against the total time being measured.
The basic formula is:
Uptime Percentage = (Total Operational Time ÷ Total Time) × 100
For example, if a website is available for 8,750 hours during a year and experiences 10 hours of downtime, its uptime percentage would be approximately 99.89%.
Although the calculation itself is simple, even small differences in uptime percentages can have a significant impact on the amount of downtime users experience.
The Uptime Formula Explained
Because uptime is measured as a percentage, many organizations aim for levels such as 99.9%, 99.99%, or even 99.999%.
At first glance, these percentages may appear nearly identical. However, the difference between them can represent hours or even days of additional service availability over the course of a year.
This is why uptime targets are often included in service level agreements (SLAs) and reliability objectives.
Understanding Common Uptime Standards
The following table illustrates how uptime percentages translate into annual downtime allowances.
| Uptime Percentage | Maximum Downtime Per Year |
|---|---|
| 99% | Approximately 3.65 Days |
| 99.9% | Approximately 8.76 Hours |
| 99.99% | Approximately 52.6 Minutes |
| 99.999% | Approximately 5.26 Minutes |
Many organizations refer to 99.999% uptime as "five nines" availability. Achieving this level of reliability requires significant investment in monitoring, redundancy, infrastructure design, and incident response capabilities.
The appropriate uptime target depends on the nature of the service. For example, an internal business application may tolerate occasional interruptions, while a financial platform, healthcare system, or e-commerce website may require much higher availability standards.
Why Uptime Matters More Than Ever
As businesses become increasingly dependent on digital services, uptime has evolved from a technical performance metric into a business-critical priority. Whether customers are shopping online, accessing cloud applications, or interacting with support portals, they expect services to be available whenever they need them.
When systems remain accessible and reliable, organizations can deliver better customer experiences, maintain productivity, and reduce operational risks. Conversely, frequent outages can quickly affect revenue, trust, and business performance.
Revenue Protection
For many organizations, every minute of downtime represents a potential loss of revenue. An unavailable e-commerce store cannot process purchases, a SaaS platform may be unable to serve subscribers, and service providers may struggle to fulfill customer requests.
Even short interruptions can create missed sales opportunities, abandoned transactions, and disruptions to business operations. The financial impact becomes even greater during peak traffic periods, promotional campaigns, or critical business events.
High uptime helps ensure that revenue-generating systems remain available when customers and employees need them most.
Customer Experience and Trust
Modern consumers have little patience for unreliable online services. If a website is unavailable or an application repeatedly experiences interruptions, users may quickly look for alternative solutions.
Consistent uptime helps create a positive customer experience by ensuring that services remain accessible and responsive. Over time, this reliability builds trust and encourages long-term customer relationships.
Organizations that invest in proactive uptime monitoring are often better equipped to identify issues before they impact users, helping maintain a consistent and dependable experience.
Brand Reputation
A company's reputation can take years to build but only moments to damage. Public outages often attract attention on social media, industry forums, and review platforms, particularly when they affect a large number of users.
Customers expect businesses to provide reliable services. Repeated disruptions can create negative perceptions about an organization's professionalism, preparedness, and ability to manage critical systems.
Maintaining high uptime demonstrates a commitment to reliability and can help strengthen brand credibility in competitive markets.
Business Continuity and Operational Resilience
Beyond customer-facing services, uptime plays an important role in business continuity. Employees depend on digital tools, communication platforms, databases, and internal systems to perform their daily responsibilities.
When these systems become unavailable, productivity can decline quickly. Teams may lose access to critical information, customer service operations may slow down, and decision-making processes can be disrupted.
Organizations that prioritize uptime are often better prepared to maintain operations during unexpected events. Through continuous monitoring, infrastructure redundancy, disaster recovery planning, and proactive risk management, they can reduce disruptions and improve overall operational resilience.
The Real Cost of Downtime
Many organizations focus on preventing outages because of their immediate impact, but the true cost of downtime often extends far beyond the initial interruption. A single outage can create financial, operational, and reputational challenges that continue long after services are restored.
Understanding these potential consequences helps businesses recognize why uptime should be treated as a strategic priority rather than simply an IT concern.
Financial Losses
The most obvious consequence of downtime is lost revenue. When customers cannot access a website, complete transactions, or use a service, businesses may lose sales and valuable opportunities.
The financial impact varies depending on the size of the organization and the nature of the outage, but even brief interruptions can become costly when critical systems are involved.
For organizations that rely heavily on digital services, reducing website downtime is often one of the most effective ways to protect revenue and maintain operational stability.
Productivity Disruptions
Downtime affects more than customers. Employees may lose access to business applications, collaboration tools, customer records, and communication systems.
As a result, routine tasks can slow down or stop entirely until services are restored. Teams may be forced to implement temporary workarounds, delaying projects and reducing overall efficiency.
The longer an outage continues, the greater the impact on productivity across the organization.
Customer Churn
Reliability plays a significant role in customer retention. When users repeatedly experience outages or service interruptions, they may begin to question whether a provider can meet their needs consistently.
In competitive industries, customers often have multiple alternatives available. Frequent downtime can encourage users to explore competing services that offer greater reliability.
Maintaining strong uptime helps organizations protect customer relationships and reduce the risk of losing business to competitors.
Recovery Costs
The work does not end when services come back online. Organizations often need to investigate the root cause of the outage, restore affected systems, verify data integrity, communicate with stakeholders, and implement measures to prevent similar incidents in the future.
These recovery efforts require time, expertise, and resources. In some cases, businesses may also face contractual penalties, compliance concerns, or additional support costs.
By investing in proactive monitoring, resilience planning, and preventative maintenance, organizations can reduce both the likelihood and the overall cost of downtime incidents.
Common Causes of Downtime
Even the most reliable systems can experience downtime. While outages are sometimes caused by unexpected events, many can be traced back to a handful of recurring issues. Understanding these causes helps organizations identify vulnerabilities and take proactive steps to improve uptime.
Hardware Failures
Physical infrastructure remains one of the most common sources of downtime. Servers, storage devices, networking equipment, and power systems all experience wear and tear over time. When critical hardware fails unexpectedly, services can become unavailable until repairs or replacements are completed.
Organizations that rely on aging infrastructure are often more vulnerable to outages. This is why many businesses invest in redundancy and preventative maintenance programs to reduce the risk of hardware-related disruptions.
Software and Configuration Errors
Modern applications are constantly evolving through updates, patches, and new feature releases. While these changes are intended to improve performance and security, they can sometimes introduce bugs or compatibility issues that affect service availability.
Configuration mistakes can be equally damaging. A seemingly minor change to a firewall rule, DNS setting, or server configuration may accidentally make a website or application inaccessible. Establishing testing procedures and change management processes can significantly reduce these risks.
Human Error
Technology is often blamed for outages, but people frequently play a role as well. Human error remains one of the leading causes of downtime across industries. An accidental deletion, incorrect system change, or poorly executed deployment can quickly disrupt critical services.
The likelihood of human error increases when organizations lack documented procedures, approval processes, or adequate training. Creating clear operational standards helps reduce mistakes and improves overall reliability.
Cybersecurity Incidents
Cyberattacks have become a major threat to uptime. Attackers often target websites, applications, and infrastructure with the goal of disrupting operations or gaining unauthorized access to systems.
Ransomware attacks, malware infections, and distributed denial-of-service (DDoS) attacks can all result in significant downtime. In many cases, the recovery process extends well beyond restoring service availability, requiring extensive investigations and remediation efforts. Maintaining strong cybersecurity controls is therefore essential for protecting both uptime and business continuity.
Third-Party Service Failures
Most businesses rely on external providers for services such as cloud hosting, DNS management, payment processing, and content delivery. While these providers generally offer high levels of reliability, they are not immune to outages.
When a third-party vendor experiences a disruption, organizations that depend on that service may also be affected. This is why businesses should carefully evaluate vendor reliability and consider backup options for mission-critical services whenever possible.
Power and Connectivity Problems
Reliable power and internet connectivity form the foundation of modern digital operations. A loss of either can quickly make websites, applications, and internal systems unavailable.
Internet service provider outages, network failures, and power interruptions can all affect uptime. Businesses that require high availability often invest in redundant internet connections, backup power solutions, and continuous monitoring to minimize the impact of these events.
If you're trying to understand why a website goes down, examining these common causes is often the first step toward identifying weaknesses and preventing future outages.
10 Proven Strategies to Improve Uptime
Achieving high uptime requires more than simply reacting to problems as they occur. Organizations that consistently maintain reliable services take a proactive approach by combining monitoring, planning, security, and resilience strategies.
1. Implement Continuous Monitoring
You cannot fix problems that you cannot see. Continuous monitoring provides instant visibility into the health and performance of websites, applications, servers, and networks. By identifying unusual behavior early, organizations can often address issues before users notice them.
Monitoring also provides valuable data that can be used to identify trends, optimize performance, and improve long-term reliability. This is one reason why proactive uptime monitoring has become an essential part of modern IT operations.
2. Build Infrastructure Redundancy
Redundancy helps ensure that a single failure does not bring down an entire service. Instead of relying on one server, network connection, or storage device, organizations create backup resources that can take over when needed.
While redundancy requires additional investment, it can dramatically reduce downtime and improve service continuity during unexpected incidents.
3. Eliminate Single Points of Failure
Many outages occur because one critical component fails and there is no alternative available. These weak points are known as single points of failure.
Regular infrastructure reviews can help organizations identify dependencies that could create availability risks. Addressing these weaknesses before a failure occurs is often far less costly than dealing with a major outage.
4. Strengthen Cybersecurity Defenses
A strong security posture directly supports uptime. Cyberattacks not only threaten sensitive data but can also make critical systems unavailable.
Organizations should regularly update software, implement access controls, monitor for suspicious activity, and maintain security awareness programs. These measures reduce the likelihood of incidents that could disrupt operations.
5. Develop a Disaster Recovery Plan
Even with the best preventative measures in place, unexpected incidents can still occur. A disaster recovery plan provides a structured process for restoring systems and services after an outage.
Effective plans clearly define recovery procedures, responsibilities, communication processes, and restoration priorities. Organizations that regularly test their disaster recovery plans are typically able to recover more quickly when disruptions occur.
6. Maintain Reliable Backups
Backups play a critical role in minimizing downtime following data loss, cyberattacks, or infrastructure failures. However, simply creating backups is not enough.
Organizations should regularly verify that backups are functioning correctly and can be restored successfully. Recovery testing helps ensure that critical data remains available when it is needed most.
7. Use Load Balancing
As demand increases, a single server can become overwhelmed and affect service availability. Load balancing distributes traffic across multiple resources, helping maintain performance and reliability even during periods of high demand.
This approach is commonly used by organizations that operate business-critical websites and applications where downtime is not an option.
8. Establish Strong Change Management Practices
Many outages occur shortly after updates or system changes are introduced. Strong change management processes help ensure that modifications are properly reviewed, tested, and documented before they are deployed.
This reduces the likelihood of avoidable disruptions while creating greater consistency across IT operations.
9. Regularly Test Systems and Recovery Procedures
Testing is one of the most overlooked aspects of uptime management. Organizations often assume their failover systems, backups, and recovery processes will work when needed, but assumptions can be costly.
Routine testing helps identify weaknesses, validate recovery procedures, and improve overall preparedness.
10. Invest in Team Training and Incident Response Readiness
Technology alone cannot guarantee high uptime. People remain a critical part of maintaining reliable services.
Employees should understand how to respond to incidents, escalate issues appropriately, and follow established recovery procedures. Regular training exercises help teams react more effectively during real-world outages and reduce recovery times.
Many organizations also incorporate ping monitoring into their monitoring strategy because it provides a simple and effective way to verify connectivity and identify potential availability issues before they become larger problems.
Uptime vs. Availability: Understanding the Difference
The terms uptime and availability are often used interchangeably, but they do not mean exactly the same thing. Understanding the difference is important because both metrics play a role in evaluating the reliability of a service.
Organizations that focus solely on uptime may overlook other factors that affect the user experience, while those that understand both metrics can develop a more complete picture of service performance.
What Uptime Measures
Uptime measures the amount of time a system, website, application, or service remains operational. It focuses specifically on whether a service is running and accessible during a given period.
For example, if a website remains online for 99.9% of the year, it has achieved 99.9% uptime. This metric is commonly used to evaluate the reliability of servers, networks, cloud environments, and business applications.
Because uptime is easy to measure and understand, it has become one of the most widely used indicators of system reliability.
What Availability Measures
Availability takes a broader view of service performance. While uptime focuses on whether a service is operational, availability considers whether users can successfully access and use the service as intended.
A system may technically be online but still provide a poor user experience due to slow response times, degraded performance, network issues, or other service disruptions. In these situations, uptime may remain high while availability suffers.
This distinction is particularly important for organizations that operate customer-facing services where performance and accessibility directly affect user satisfaction.
Why Businesses Should Track Both Metrics
Uptime and availability work best when viewed together. Uptime helps organizations understand how often services remain operational, while availability provides insight into the actual experience users receive.
By monitoring both metrics, businesses can identify issues that might otherwise go unnoticed. A service that rarely goes offline but frequently experiences performance problems may still create frustration for users and negatively impact business outcomes.
Organizations that prioritize both uptime and availability are generally better positioned to deliver reliable services, maintain customer trust, and support long-term operational resilience.
Key Metrics That Support High Uptime
Although uptime is one of the most important reliability metrics, it does not tell the entire story. Organizations often rely on several supporting measurements to evaluate system performance, identify weaknesses, and improve recovery capabilities.
These metrics provide deeper insights into how frequently failures occur and how quickly systems can recover when disruptions happen.
Mean Time Between Failures (MTBF)
Mean Time Between Failures, commonly referred to as MTBF, measures the average amount of time a system operates before experiencing a failure.
A higher MTBF generally indicates greater reliability because it means failures occur less frequently. Organizations often use MTBF to evaluate infrastructure performance and identify opportunities for improvement.
While no system is immune to failures, increasing the average time between incidents can significantly contribute to higher uptime over the long term.
Mean Time to Repair (MTTR)
Mean Time to Repair, or MTTR, measures how quickly a system can be restored after a failure occurs.
Even highly reliable systems will occasionally experience issues. What often separates resilient organizations from others is their ability to respond and recover efficiently.
A lower MTTR means downtime is minimized because teams can identify, diagnose, and resolve problems more quickly. Monitoring tools, documented procedures, and trained personnel all contribute to reducing recovery times.
Recovery Time Objective (RTO)
Recovery Time Objective defines the maximum amount of time an organization can tolerate a service being unavailable following an outage or disaster.
For example, a company may determine that a critical business application must be restored within one hour of an incident. This one-hour target becomes the application's RTO.
Establishing realistic RTOs helps organizations prioritize recovery efforts and align technology investments with business requirements.
Recovery Point Objective (RPO)
Recovery Point Objective focuses on data rather than time. It defines the maximum amount of data loss an organization is willing to accept following an incident.
For example, if backups are performed every 15 minutes, the organization may have an RPO of 15 minutes because up to 15 minutes of data could potentially be lost during a failure.
Understanding RPO requirements helps businesses design appropriate backup strategies and ensure that critical information can be recovered when needed.
Building a Long-Term Uptime Strategy
Improving uptime is not a one-time project. Organizations that consistently achieve high availability treat reliability as an ongoing business objective that requires continuous monitoring, evaluation, and improvement.
Rather than focusing solely on technology, successful uptime strategies combine people, processes, and infrastructure to create a resilient operating environment.
Align Reliability Goals With Business Objectives
Not every system requires the same level of uptime. A critical customer-facing application may demand near-continuous availability, while an internal tool may be able to tolerate occasional interruptions.
Organizations should define uptime goals based on business impact, customer expectations, operational requirements, and risk tolerance. This approach helps ensure that resources are invested where they deliver the greatest value.
Develop a Business Continuity Plan
Business continuity planning plays a vital role in maintaining uptime during unexpected events. A comprehensive plan outlines how critical operations will continue when disruptions occur and identifies the processes needed to restore services quickly.
When combined with disaster recovery planning, business continuity initiatives help organizations minimize downtime and maintain essential operations under challenging circumstances.
Regularly Assess Risks and Vulnerabilities
Technology environments constantly evolve. New applications, infrastructure changes, security threats, and business requirements can introduce new risks over time.
Regular risk assessments help organizations identify vulnerabilities before they result in outages. Addressing these issues proactively is often far less costly than responding to a major disruption after it occurs.
Organizations should also remember to monitor domain expiration dates and other often-overlooked dependencies that can unexpectedly affect service availability.
Continuously Improve Operational Resilience
High uptime is not achieved through a single tool or process. It requires a commitment to ongoing improvement.
Organizations should review incident reports, analyze performance data, test recovery procedures, and refine operational practices on a regular basis. These efforts help strengthen resilience and improve the ability to withstand future disruptions.
Over time, a culture of continuous improvement can significantly enhance uptime while reducing the operational and financial risks associated with downtime.
Frequently Asked Questions About Uptime
Many organizations understand that uptime is important, but they often have questions about what constitutes good performance and how uptime should be measured. The following answers address some of the most common questions about uptime and reliability.
What Is Considered Good Uptime?
The answer depends on the type of service being provided and the expectations of its users.
For many businesses, 99.9% uptime is considered a strong benchmark because it limits annual downtime to less than nine hours. Organizations that operate mission-critical applications, financial services, healthcare systems, or large e-commerce platforms often target 99.99% uptime or higher.
The key is to establish uptime goals that align with business requirements and customer expectations. A service that supports essential business operations typically requires stricter availability standards than a non-critical internal application.
Is 100% Uptime Possible?
While many organizations strive for perfect reliability, achieving true 100% uptime is extremely difficult.
Even the most advanced infrastructure can be affected by unexpected hardware failures, software defects, cybersecurity incidents, network disruptions, or human error. Planned maintenance activities may also require temporary service interruptions.
For this reason, most organizations focus on maximizing uptime through redundancy, monitoring, disaster recovery planning, and continuous improvement rather than pursuing an unrealistic goal of absolute perfection.
What Does Five Nines Uptime Mean?
Five nines uptime refers to an availability level of 99.999%.
This standard is often used to describe highly reliable systems and services that experience very little downtime throughout the year. At this level, annual downtime is limited to approximately five minutes.
Achieving five nines uptime typically requires sophisticated infrastructure, redundant systems, comprehensive monitoring, robust cybersecurity controls, and well-tested recovery procedures.
Because of the investment required, not every organization needs to pursue this level of availability. The appropriate target should be based on business needs and risk tolerance.
How Often Should Uptime Be Monitored?
Uptime should be monitored continuously whenever possible.
Continuous monitoring allows organizations to detect outages, performance issues, and infrastructure problems as soon as they occur. The faster a problem is identified, the faster teams can respond and minimize the impact on users.
Modern monitoring solutions can track websites, servers, applications, networks, and other critical services around the clock. Continuous monitoring is one of the most effective ways to improve reliability and reduce downtime over time.
Conclusion
Uptime is far more than a technical metric. It is a direct reflection of how reliably an organization can deliver services, support customers, and maintain business operations.
By measuring uptime, understanding the causes of downtime, and implementing proven reliability strategies, organizations can reduce disruptions and improve overall service performance. Continuous monitoring, infrastructure redundancy, cybersecurity protections, disaster recovery planning, and regular testing all contribute to stronger uptime outcomes.
While no system can completely eliminate the risk of outages, businesses that take a proactive approach are better positioned to protect revenue, maintain customer trust, and strengthen operational resilience.
As digital services continue to play an increasingly important role in everyday business operations, investing in uptime is ultimately an investment in reliability, continuity, and long-term success.